同盾科技两篇论文入选人工智能顶级会议AAAI
- 2020-04-13 16:43
- 科技圈
近期,AAAI 2020 (the 34th AAAI Conference on Artificial Intelligence)在美国纽约召开。在这场人工智能领域的顶级会议中,同盾科技共有两篇论文《Improving Question Generation with Sentence-level Semantic Matching and Answer Position Inferring》和《Rethinking the Bottom-Up Framework for Query-based Video Localization》被选为口头报告(oral presentation),两篇论文分别为文本问答系统(QA)和视频问答系统(VQA)相关领域最前沿研究成果,分别与佛罗里达大学和浙江大学合作。
截止到2020年,AAAI已经成功举办了34届,被公认为人工智能领域的权威会议,也是各科技公司竞技的赛场,同时更是未来人工智能产业发展方向的重要风向标。
近日,工业和信息化部新闻发言人、信息技术发展司司长谢少锋表示,在疫情期间,人工智能技术得到了有效运用,据不完全统计,有20多款人工智能产品和应用在疫情监测、疾病诊断、药物研发等方面发挥了重要的作用。而同盾智能预测系统和智能回访平台也在疫情期间驰援一线协助抗疫。
同时,随着“新基建”成为当下国内经济焦点之一,中国要加快5G、大数据中心、人工智能等新型基础设施建设进度,产业的网络化、数字化、智能化发展已经成为大势所趋。
本次AAAI大会共收到了8843篇投稿,7737篇论文进入评审,最终录取1591篇论文,其中仅有453篇(约5.9%接受率)作为会议口头报告。会议论文主题涵盖计算机视觉、自然语言处理、机器学习、知识表达、逻辑推理等多个前沿领域,同盾作为重要的中国企业代表,在当前人工智能行业最前沿的竞技舞台上取得亮眼表现,其背后反映出很强的科研创新能力。
以本次入选的《Improving Question Generation with Sentence-level Semantic Matching and Answer Position Inferring》为例。
问答系统是自然语言处理领域的一个重要研究方向,近年来各大国际会议、期刊都发表了大量与问答系统相关的研究成果,实际工业界中也有不少落地的应用场景,核心算法涉及机器学习、深度学习等知识。问答系统(Q&A)的主要研究点包括模型构建、对问题/答案编码、引入语义特征、引入强化学习、内容选择、问题类型建模、引入上下文信息以及实际应用场景问题解决等。
同盾的论文主要聚焦问答系统(Q&A)的反问题---问题生成(Question Generation,Q&G)。问题生成的目的是在给定上下文和相应答案的情况下生成语义相关的问题,问题生成在智能对话系统、教育场景、问答助手、智能投顾、医疗问诊等应用领域具有巨大的潜力。
问题生成任务可分为两类:一类是基于规则的方法,即在不深入理解上下文语义的情况下手动设计词汇规则或模板,将上下文转换成问题。另一类是基于神经网络的、直接从语句片段中生成问题词汇的方法,包括序列-序列模型(seq-to-seq)、编码器解码器(encoder-decoder)等。本文讨论的是一种基于神经网络的问题生成方法。
目前,基于神经网络的问题生成模型主要面临以下两个问题:(1)错误的关键词和疑问词:模型可能会使用错误的关键词和疑问词来提问;(2)糟糕的复制机制:模型复制与答案语义无关的上下文单词。
同盾及佛大合作者认为,现有的基于神经网络的问题生成模型之所以出现上述两个问题是因为:(1)解码器在生成过程中可能只关注局部词语义而忽略全局问题语义;(2)复制机制没有很好地利用答案位置感知特征,导致从输入中复制与答案无关的上下文单词。
为了解决这两个问题,同盾研究人员提出以多任务学习(Multi-Task Learning,MTL)的方式学习句子级语义,以及引入答案位置感知,「Our model」为本文提出模型在相同实验条件下生成的问题。图 1 给出本文提出的具有句子级语义匹配、答案位置推断和门控融合的神经问题生成模型图。
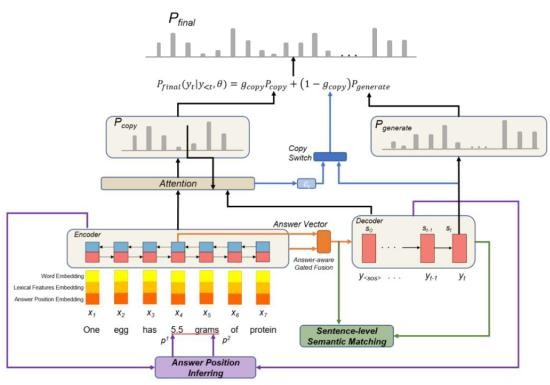
1
(图1)
句子级别语义匹配见图 2 所示。

2
(图 2. 句子级语义匹配)
答案位置推断(Answer Position Inferring):引入双向注意力流网络 [3] 推断答案位置,见图 3。

3
(图 3. 答案位置推断框架)
采用句子对问题(Sentence-to-Question,S2Q)注意和问题对句子(Question-to-Sentence,Q2S)注意来强调每个句子词和每个问题词之间的相互语义关联,并利用相似的注意机制得到了问题感知的句子表征 H 和句子感知的问题表征 S:

34
然后,使用两个两层双向 LSTMs 来捕获以问题为条件的句子词之间的相互作用。答案起始索引和结束索引由输出层使用 Softmax 函数预测:

5
其中,f 函数是一个可训练的多层感知(MLP)网络。使用真值答案起始标记 y1 和结束标记的负对数似然来计算损失:

6
为了在多任务学习方法中联合训练生成模型和所提出的模块,训练过程中的总损失函数记为:

5
同盾研究人员在 SQuAD 和 MARCO 两个数据集上进行了实验,使用 NQG++[1]、Point-generator[2] 以及 SOTA 模型、门控自注意力机制模型等作为基线对比算法。表 3 给出了 SQuAD 和 MS-MARCO 数据集上不同模型的主要指标,在文章所述的实验条件下,本文提出的模型在全部主要指标上都优于基线对比算法。
表 3. SQuAD 和 MARCO 数据集主要指标的模型性能比较

8
小结:与现有的问答系统、问题生成模型的处理方式不同,本文并不是通过引入更多的有效特征或者改进复制机制本身等来改进模型效果,而是直接在经典序列-序列模型(seq-to-seq)中增加了两个模块:句子级语义匹配模块和答案位置推断模块。此外,利用答案感知门控融合机制来增强解码器的初始状态,从而进一步改进模型的处理效果。
从学术殿堂到数字经济基础设施建设前线
作为以场景应用和产品研发见长的同盾,是首次问鼎国际人工智能顶级会议,而同盾的创新之路不会止步,同盾一直致力于用人工智能、大数据等手段构建数字经济的新型基础设施,致力于让智能分析决策成为数字时代通用基础设施。就如同水、电一样无处不在,智能决策将是驱动一切商业发展的核心,所有的企业及政务机关都需要依靠一套分析和决策系统。
目前,同盾智能分析决策在金融风控、信用经济、企业数字化转型、智慧城市等领域正在发挥重要作用。
站在历史性拐点,智能决策能力或将成为未来衡量企业、城市乃至社会治理综合实力的一个重要指标,智能决策的未来将有赖于更多科技企业投身到研发和创新之中。




- 索尼加强监管PS4游戏中情色内容 引部分开发者不满2019-06-13 10:24
- 腾讯京东成乐融致新新晋股东 乐视网盘中涨超9%2019-06-12 14:03
- “向新而行 ,强大中国车”比亚迪演绎强大中国车2019-05-30 13:57
- 獐子岛扇贝又又又跑路了 证监会和交易所看不下去了2019-05-24 17:27
- “深海勇士”:碧海寻声2019-05-14 13:50


-
2
 哪个比特币钱包更安全,选择币信靠谱吗?
哪个比特币钱包更安全,选择币信靠谱吗?
2021-02-05 16:02
-
3
 受央视关注,必要科技C2M模式赋予产业发展新动能
受央视关注,必要科技C2M模式赋予产业发展新动能
2021-02-04 16:43
-
4
 腾讯Light·公益创新挑战赛正式启动 腾讯优图向科技公益深度探索
腾讯Light·公益创新挑战赛正式启动 腾讯优图向科技公益深度探索
2020-12-30 15:50
-
5
 首届中国数字冰雪运动会成都站暨线下滑雪体验赛圆满落幕
首届中国数字冰雪运动会成都站暨线下滑雪体验赛圆满落幕
2020-11-30 10:30